This article’s initial intention is to provide a framework for the various algorithms referred to when discussing CSS algorithms, which has become a recurring theme for the author. However, engaging in a conversation about these algorithms requires substantial foundational knowledge related to the domain—the browser itself. This encompasses numerous aspects of Computer Science, which will also be explored in due course.
Before delving into what algorithms in CSS mean, it is essential to establish a robust mental model of how browsers operate for both the reader and the author. While numerous valuable resources are available on this topic that should certainly be consulted, the author aims to present this explanation in their own words. This will serve as a personal reference point for future use when specific details slip from memory. 
It’s essential to include a brief disclaimer that will likely appear at the beginning of each post: Browsers are incredibly intricate and expansive software systems, making it impossible to cover every aspect comprehensively. There will inevitably be significant portions omitted; readers are encouraged to comment if they identify any omissions. Additionally, these posts may not be perfectly polished; however, given that this is an online platform, errors can be corrected by attentive readers—feedback on typos or inaccuracies is welcomed.
Now, without further delay, let’s explore browser mechanics! Browsers are fascinating entities, and it’s hoped that some enthusiasm can be conveyed through enthusiastic punctuation along the way. The first step involves acquiring data; here we go!
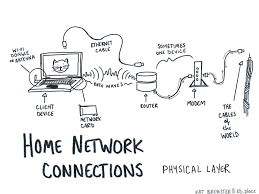
Step 1: Provide data; here is the information. The browser, also known as the client, front-end, or user agent, receives a stream of bytes from a server in response to an HTTP request. This can be visualised as a person at a computer sending an HTTP request to a server and receiving a byte stream in return. When the client seeks data from the server, this occurs when a URL—such as not laura. Com—is entered into the address bar.
The domain name notlaura.com directs to a physical server located somewhere globally, managed by Webfaction, which sends the requested information back to the browser in 8-bit byte format. These bytes can eventually be interpreted into HTML, CSS, and JavaScript. Although back-end programming languages may have been used to generate that HTML, CSS, and JS content, this distinction is irrelevant to the browser itself. For clarity’s sake, it is crucial to define what constitutes a server: it is either a physical machine or software explicitly designed to provide services to clients.
In terms of websites, servers deliver website files upon request and are responsible for storing data and executing computations when needed. The term server may refer either to the actual physical computer—which often resembles stacks of futuristic pizza boxes—or to a collection of programs that respond with data upon receiving requests.
Step 2: Convert byte data to Unicode code points
Upon receiving the byte stream, the browser must convert these bytes into tree-like data structures (which will be elaborated on later). The two primary trees of interest here are:
1. The HTML tree, commonly referred to as the DOM (Document Object Model).
2. The CSS tree, known as the CSSOM (CSS Object Model), which, while equally important, often receives less recognition.
Let’s explore how this conversion occurs. It is important to note that bytes do not simply transform into trees. A personal commitment has been made to avoid using the phrase turn into in programming discussions, as it can imply a sense of magic that does not exist in this context. Readers are encouraged to join in this effort! If any instances of turning X into Y are found in previous writings, please provide feedback.
Now, what exactly is a byte? A byte consists of eight bits—essentially a collection of eight 1s and 0s. These bytes are frequently represented in hexadecimal format (which is also used for hex colours). Below is an example of a hexadecimal byte sequence from a small CSS ruleset:
55 2b 36 38 20 55 2b 33 31 20 55 2b 32 30
20 55 2b 37 42
20
55
2b
32
30
20
55
2b
36
33
…
(continues)
To effectively use these bytes, web standards dictate that the browser (also known as the user agent) must decode them into Unicode code points for subsequent parsing and tokenisation (the focus of part two!). The server plays a crucial role by sending a header that specifies the encoding used for these bytes so that the browser can accurately decode them into Unicode code points.
For instance, here is how the byte mentioned above sequence appears when decoded into Unicode code points:
U+68 U+31 U+20 U+7B U+20 U+63 U+6F U+6C U+6F U+72 U+3A U+20 U+70 U+65 U+61 U+63 U+68 U+70 …
It would be beneficial to present this sequence translated into English characters: h1 colour:
It should be noted that there are additional aspects to investigate regarding this step, such as whether there is a distinction between a byte sequence and a byte stream. Furthermore, one might wonder about the significance of the leading zeros in code points and the 0x prefixes for bytes in the Infra Standard. This leads to a question about what exactly the Infra Standard entails. However, to keep this article progressing, those inquiries will be set aside for now.
A significant takeaway from Computer Science is that while decoded bytes—represented as h1 colour: peach puff—carry meaning for humans, they hold no intrinsic value for computers when viewed in isolation. Ultimately, it is up to the user agent to convert these characters into a format from which it can derive instructions for rendering them visually. This format will take shape as trees in upcoming discussions. Additionally, it appears that the term encode refers to converting data into a character encoding more aligned with binary representation. At the same time, decode pertains to transforming it closer to recognisable English characters. These serve as effective alternatives for turn into.
As for what has transpired thus far in Browser Mechanics Explained? Only a little has occurred yet; only hexadecimal bytes have been decoded into Unicode code points. This represents roughly 1 out of 100,000 tasks performed by a browser, indicating that this could evolve into an extensive series of discussions. However, that’s all for today! To conclude this section, here’s a simplified and somewhat imprecise diagram illustrating what the process of transforming data into trees will entail (with the red dot indicating our current position).
Once the DOM and CSSOM have been established, the next step is to form the Render Tree. That will come in due time! At this moment, however, the priority is to finalise and publish this blog post and step away from the computer.
How Maxthon Browser Decodes Bytes to Unicode
1. Understanding the Basics: Before decoding bytes to Unicode, it’s essential to know what each term means. Bytes are sequences of digits that represent data, while Unicode is a standardised system for encoding and representing text in different languages.
2. Initiating the Process: When you visit a website using Maxthon Browser, it receives raw byte data from the server. This data typically represents web content like HTML files, images, or scripts.
3. Detecting Encoding: The browser first examines the HTTP headers or meta tags in the webpage to determine the character encoding used by the site. Common encodings include UTF-8, ISO-8859-1, and Windows-1252.
4. Using Libraries for Conversion: Once the encoding is identified, Maxthon utilises built-in libraries to convert the byte sequences into readable characters based on the detected encoding.
5. Handling Errors Gracefully: If there’s an issue during decoding—like unsupported characters or incorrect encoding—the browser implements error-handling mechanisms to ensure that users still see as much content as possible without significant display issues.
6. Displaying Content: After successful conversion, Maxthon renders the decoded Unicode text onto your screen, allowing you to interact with web pages seamlessly and effectively in your preferred language.
7. User Preferences: Users can adjust settings within Maxthon Browser to override default encoding choices if needed, allowing for greater customisation based on personal preferences or viewing habits.
8. Maintaining Compatibility: Additionally, Maxthon continually updates its algorithms and libraries to support emerging standards and formats in text representation for better cross-platform compatibility.
9. Feedback Loop: Finally, user feedback plays a role in improving this process; reporting issues with character representation helps developers refine decoding strategies for future versions of the browser.
