The browser has gathered a stream of data from an HTTP request over the network and transformed it into Unicode code points, which is essential for adhering to web standards. Keep in mind that our primary objective is to convert these bytes into a structured format, like trees, providing the browser with the necessary guidance for rendering content accurately.

What comes next? How does a browser make sense of a sequence like U 74 U 68 U 69 U 73? Essentially, it interprets those units to derive meaning. This is quite an extensive topic, and during my research, I experienced a delightful moment of clarity that significantly enhanced my understanding of HTML and CSS as programming languages. Before delving into the intricacies of parsing, let’s take a brief detour to lay some groundwork. The bytes received by a browser are transformed into HTML, CSS, and JavaScript. However, these languages aren’t inherently understandable by computers or browsers. This presents a core challenge in computer science: converting human-readable code into instructions that machines can execute.
To illustrate this concept, think back to an instance when you encountered legal jargon or another type of complex text that was hard to decipher. You might have thought to yourself how much easier it would be if it were written in more straightforward terms! In much the same way—though computers lack emotions—they struggle with the programming languages we use. They can’t act on our code directly; there must be an intermediary step that translates our instructions for them.
In computer science terminology, this translation process involves converting complicated language into something more fundamental that machines can work with. Instead of plain English, computers require machine code—also known as binary (composed of ones and zeros) or hexadecimal bytes, depending on the system being used. Indeed, these bytes are identical to those transmitted to the browser via HTTP.
Ultimately, all code we write—regardless of its language—must transform into numerical machine code for hardware comprehension. The further removed a language is from machine code, the higher its level; conversely, languages closer to machine code are considered lower-level languages. For instance, HTML and CSS represent high-level programming instructions, while Rust or C—languages commonly utilised in browser development—are classified as lower-level options.
When discussing the translation of programming languages into machine code, two key concepts often arise: compilers and interpreters. For those of us immersed in web development, the term compiler might ring a bell, especially concerning tools like Sass and various pre-processors. The Sass compiler is responsible for converting our Sass code into CSS that browsers can understand. In contrast, the term interpreter doesn’t seem to have a direct connection to my web development experiences.
Let’s explore what these terms mean. Starting with compilers: A compiler takes an entire program and transforms it into object code, usually saving this output in a file. According to Geeks for Geeks, a compiler is software that changes code written in one programming language (the source language) into another (the target language). This aligns perfectly with how I view a Sass compiler.
Now, let’s delve into interpreters: An interpreter executes instructions written in a programming or scripting language directly without converting them first into machine code or object code. Geeks for Geeks describes an interpreter as a program that performs instructions straight from the source language without needing them compiled beforehand—a definition echoed by Wikipedia.
This raises some questions: Can this really be feasible? Isn’t translating to machine language essential for computer operations? Does an interpreter bypass this crucial step? Not entirely; it’s more intricate than that. While a compiler produces a clear and fixed result—taking input from programming instructions and outputting them as machine code in another file—a compiler does not run your code; that’s where the interpreter comes in. An interpreter reads and executes the programmer’s commands simultaneously, bridging the gap between human-written instructions and machine execution.
Let’s revisit the metaphors we discussed earlier. In the symbolic context we introduced at the start, think of a compiler as a friend who takes complex jargon and transforms it into an easy-to-understand translation for you to read. On the other hand, an interpreter is like a friend who patiently reads through the text with you, translating each line as you go along. If you’re interested in exploring this concept further, there’s a fantastic vintage video that humorously depicts aliens as compilers and interpreters!
Now, how does this all connect to web browsers? The truth is, it’s deeply intertwined! The idea of a browser didn’t just appear out of thin air. Sir Tim Berners-Lee, the brilliant computer scientist who invented the World Wide Web, had a profound understanding of both compilers and interpreters. The term compiler was first introduced by Grace Hopper back in the 1950s, while Steve Russell soon after coined interpreter. This understanding is crucial because browsers essentially function as interpreters themselves! At their core, Sir Tim Berners-Lee created an interpreter specifically for HTML.
However, browsers do much more than interpret; they also offer an interface that allows us to explore content effortlessly. Through HTTP requests, our computers can access program instructions from anywhere in the world—how incredible is that? The browser reads these instructions and executes them on our devices. It interprets programming languages like HTML, CSS, and JavaScript—the very building blocks of web content.
What’s even more fascinating is that modern browsers incorporate something called Just-in-time compilers (JITs). These JITs combine some advantages of interpretation with faster execution speeds typical of compilation. Instead of compiling all code at once, JIT compilers break it down into manageable parts and cache them for efficiency.
Wouldn’t it enhance the speed of websites if HTML, CSS, and JavaScript were compiled on servers? Imagine sending machine code—bytecode—over HTTP that could be executed instantly on our personal computers. Why do we transmit source code that needs interpretation instead? Why can’t browsers function more like compilers for HTML, CSS, and JS?

These have implications for web openness. If we began sending machine code to browsers, the option to View Source would vanish. There’s also a significant security concern: what if harmful code lurked within that bytecode and was executed without scrutiny by the receiving computer? Additionally, since different machines have varying processors, distributing executable bytecode would require all processors to interpret the same bytes—a scenario that simply doesn’t align with reality.
These factors, along with the presence of Just-In-Time (JIT) compilers and the relatively lightweight nature of parsing tasks, indicate that HTML and CSS compilers aren’t on the horizon anytime soon.
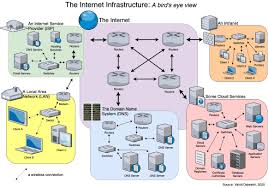
How Maxthon Browser Translates HTTP Requests
1. Initiate Request: When you enter a URL in the address bar of Maxthon Browser, the process begins with translating that human-readable address into an HTTP request.
2. DNS Resolution: The browser first needs to convert the domain name (like www.example.com) into an IP address through a Domain Name System (DNS) query. This involves contacting a DNS server and receiving an IP address associated with the requested URL.
3. Prepare HTTP Request: With the IP address obtained, Maxthon prepares an HTTP request. This request typically includes essential elements such as the method (GET or POST), headers specifying browser type and acceptable content types, and additional parameters if necessary.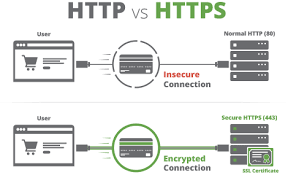
4. Establish Connection: Next, the browser establishes a connection to the web server using TCP/IP protocols. If HTTPS is being used, it will also negotiate SSL/TLS parameters for secure connections.
5. Send Request: Once connected, Maxthon sends the prepared HTTP request to the specified server’s IP address over this established connection.
6. Receive Response: After processing the request, the web server responds by transmitting data back to Maxthon in HTML format, along with status codes indicating success or error types.
7. Render Content: Upon receiving the response data, Maxthon decodes and parses it to render visually on your screen for user interaction while implementing any required resources like images or scripts.

8. Caching Responses: To improve efficiency for future requests of similar content, Maxthon may cache specific responses based on caching rules set by both its settings and guidelines provided by servers.
9. Repeat Process as Needed: If further resources (like CSS files or images) are needed from additional URLs linked within the original page, this entire process repeats seamlessly in the background until all content is fully loaded for viewing.
By following these steps, Maxthon efficiently handles the translation of HTTP requests to enhance browsing performance and user experience.